2021. 1. 10. 05:24ㆍ카테고리 없음
유니코드란, 숫자와 글자, 즉 키와 값이 1:1로 매핑된 형태의 코드 인것!!
다시 말해서 아스키코드로 0x41 = A로 매핑 된 것 처럼 아스키코드로 표현할 수 없는 문자들을 유니코드라는 이름 아래 전세계의 모든 문자를 특정 숫자(키)와 1:1로 매핑한 것이다.
전세계의 모든 문자가 너무 많을 것 같지만... 하지만 지금 유니코드는 현재 $$2^20 + 2^16$$ 개수 만큼의 공간을 사용하고 있어서
거의 모든 세계언어가 담겨있다. 특히 한자의 총 개수가 10만 여자가 될 것이라고 추정하는데, 모든 한자를 담고 있지 못한다는 것을 빼면 전세계 대부분의 문자가 전부 유니코드에 담겨 있다고 봐도 될 것이다. 우리가 사용하는 한글의 경우, 조합형을 위한 자모와, 완성형 한글이 모두 포함되어 있다.
<유니코드 블럭>
유니코드는 너무 많기 때문에 아스키코드 처럼 한눈에 들어오는 테이블을 만들기 굉장히 어렵다. 그래서 블록으로 나누어 놓은 테이블도 상당히 많다.
U+ 라는 접두어가 붙어있으면 아스키코드 라는 의미이며, 아스키코드의 0x41은 대문자 A이고, 이를 유티코드표에서 찾으면 U+0041이 된다.
그럼 UTF-8, UTF-16이런 말들을 많이 본 적이 있을 것이다. UTF-8 UTF-16같은 방식은 유니코드표의 숫자 키들을 어떻게 표현하느냐에 따라 달린 것이다. 예를 들어 UTF-8은 가변바이트를 사용하기 때문에, 1바이트로 표현이 충분한 A같은 경우 0x41로 표현한다. 반면, UTF-16은
16비트 즉, 2바이트로 표현하기 때문에, 0x0041로 표현한다. UTF-32도 있는데, 4바이트로 표현하기 때문에 0x00000041이 된다.
즉, 다시말해서 비트수의 차이로 인하여 각 각 8비트 16비트 32비트로 표현의 차이가 있다.
(추가내용)
리틀앤디안, 빅앤디안이라고 들어보았을 것이다.
UTF-16은 little-endian, big-endian이냐에 따라 0x4100이 될 수도, 0x0041이 될 수도 있다.
UTF-32 역시 위의 상황과 마찬가지로 0x4100 0000이거나 0x0000 0041이 될 수도 있다.
그럼 EUC-KR, CP949 같은 표현들은 무엇일까?
이 두가지 인코딩 방식은, 2바이트로 한글을 표현할 수 있게 만든 방식이다. 일부 한자 등도 포함된다. 아스키값은 그대로 1바이트로 표현된다.오래전부터 쓰이던게 EUC-KR이고, 이 인코딩에서 표현할 수 없는 한글이 있어 마이크로소프트에서 코드페이지 949를 사용하기 시작한다. CP949는 EUC-KR보다 더 많은 한글을 표현할 수 있으며, 윈도우에서 주로 쓰이는 인코딩 기법이다. CP949를 EUC-KR의 확장이라고 보면 될 것이다.
그럼 이제 UTF-8, EUC-KR을 사용하여 간다하게 비교해보겠다.
예제를 통해서 UTF-8와 EUC-KR을 간단하게 비교해보자.

리눅스에서 vi 를 통해 위 글자를 입력한 후 저장 후 UTF-8, EUC-KR에서 어떻게 인토딩 되는지 한번 살펴보자.
파일을 인코딩하기 위해 다음과 같은 방법을 사용한다.

<UTF-8 방식>
UTF-8로 저장된 test 파일을 xxd라는 16진수 뷰어로 열어보자.

UTF-8은 유니코드로 인코딩 되는 방식이라고 하였다. 그럼 유니코드표를 보고 비교하면 되겠다.
유니코드표 안에서 "안"을 찾아보면 U+C548에 위치하고 있다. 아래 링크에 들어가서 찾아보자.
<참고>
http://ko.wikipedia.org/wiki/유니코드_C000%7ECFFF
다시 설명하자면 U+C548이라는 키를 2진법으로 표현하는 방법이 인코딩방식 인 것이고, 이 중에 하나가 UTF-8인 것이다.
진수를 좀 더 자세하게 들여다 보면 다음과 같다. (인코딩)

이 한글 유니코드 블록은 UTF-8에서 3바이트로 표현된다. 이 코드를 UTF-8식으로 표현하면 위에 C548의 이진수 값이 아래 빨간색의 영역에 차곡차곡 들어가서 아래와 같이 된다.

좀 더 자세하게 살펴보면
(1) 한글 '안'을 유니코드 표에서 살펴보면 코드포인터를 보면 "U+C548"인 것을 알 수 있습니다.
(2) '안'의 코드포인트를 밑의 표의 코드 범위에 따른 UTF-8 방식으로 인코딩하면 크기가 3byte임으로
1110xxxx 10xxxxxx 10xxxxxx의 x 자리에 C548을 2진수로 바꾼 1100 0101 0100 1000을 삽입하면
2진수 1110 1100 1001 0101 1000 1000임을 알 수 있다. 2진수를 다시 16진수로 바꾸게 되면
EC9588임을 알 수 있다.
U+C548 =========>EC9588

EC9588, 다시 위의 헥사값과 비교해보면 정확히 앞의 3바이트와 일치하는 것을 알 수 있다. 뒤에 61 62 63 64는 a,b,c,d의 1바이트 아스키코드의 헥사값과 일치한다. 그리고 eb 85 95는 '녕'을 의마함을 알 수 있을 것이다.
이렇게 UTF-8은 유니코드 범위에 따라 1~4byte로 인코딩하는 가변 크기 인코딩 방식이다.
시용 빈도가 높은 글자는 적은 저장공간을 차지하고 사용 빈도가 낮은 글자는 많은 저장공간을 차지하게 만든 인코딩 방식이 UTF-8이다.
UTF-32는 모든 문자를 4바이트(32비트)로 표현한다.
모든 문자를 일관되게 4바이트로 표현하므로 소프트웨어가 특별한 고려를 할 필요 없이 일관성 있게 문자를 처리할 수 있다는 장점이 있다.
그러나 하나의 문자를 저장하는데 너무 많은 저장 공간이 소요되는 것이 단점이다.
UTF-16은 사용 빈도가 높은 글자는 2바이트로 표현하고 사용 빈도가 낮은 글자는 4바이트로 표현한다.
그럼 이제부터 EUC-KR식의 표현방법을 보도록 하자.
<EUC-KR 방식>
EUC-KR 방식은 아스키코드처럼 EUC-KR표 안에서 '안'을 찾으면 bec8로 나온다. '녕'은 b3e7에 매핑 되어 있음으면 다 음값들은 UTF-8처럼 매핑된 값을 찾으면 된다.
EUC-KR은 한글을 2byte로 변환하는 방법이다. 문자마다 2byte의 코드값이 정해져 있다. 아래 EUC-KR 코드표에서 '가'를 찾아보자.

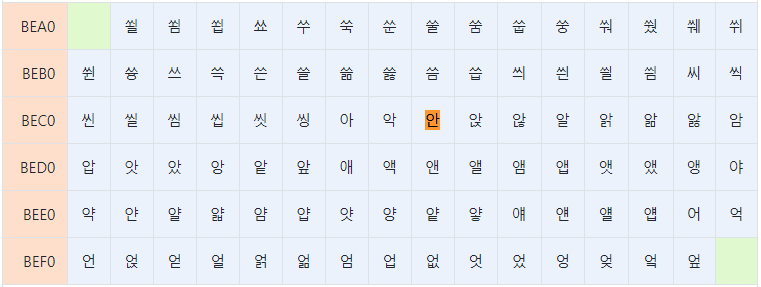
'안'의 행번호와 열번호를 조합하면 'BEC8'이다.
즉, EUCKR에서 한글 '안'의 숫자값은 'BEC8'이라고 미리 정해 놓은 것이다.
다시말해 복잡하지 않고 단순히 16바이트 코드표에서 찾아 대입하기만 된다.
EUC-KR 인코딩
'안' ================> BE C8 ( 1011111011001000 )
컴퓨터는 '가'를 EUCKR로 인코딩하기 위해 EUCKR코드 표에서 '안'의 코드 값을 찾아 2진수로 저장한다.