2021. 6. 12. 23:21ㆍAI-딥러닝/실습(학습모델 비교)
정확도 개선을 위해 새로운 딥러닝 모델을 탐색하기 시작했다.. 물론 VGGNet도 앞 글에서 소개를 했지만 좀 더 다른 모델이 없을까 탐색해보는 것도 나쁘지 않다는 생각을 하게 되었다.
그러다 찾은 모델이 하나가 있는데
https://github.com/zalandoresearch/fashion-mnist
zalandoresearch/fashion-mnist
A MNIST-like fashion product database. Benchmark :point_down: - zalandoresearch/fashion-mnist
github.com
벤치마크 기중 정확도 0.963으로 2등이다.
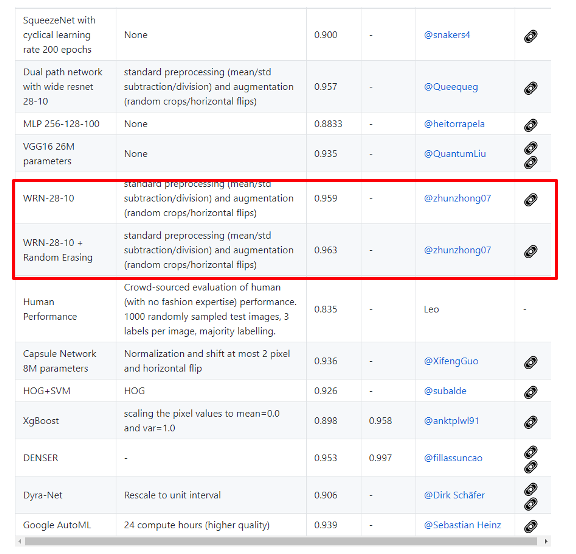
이 WRN-28-10 + Random Erasing은 좀 특이한 방법을 사용하여 CNN연산을 수행한다.
순서는 다음과 같다.
1. 학습시 Train데이터에 랜덤으로 모자이크 생성
2. 이미지의 일부분을 랜덤하게 손실시킨다.(내가 해석하기에는 이미지 DROPOUT같은 느낌...)
3. 모델의 분류 성능을 향상 시킨 모델을 준비
4. 학습에 적용


이 모델의 기본 학습모델은 ResNet과 WRN을 사용한다.
자 그럼 Fashion_MNIST 데이터셋에 이 모델을 적용해보자
일단, 학습 데이터셋과 옵티마이져 옵션들을 다음과 같이 설정했다.
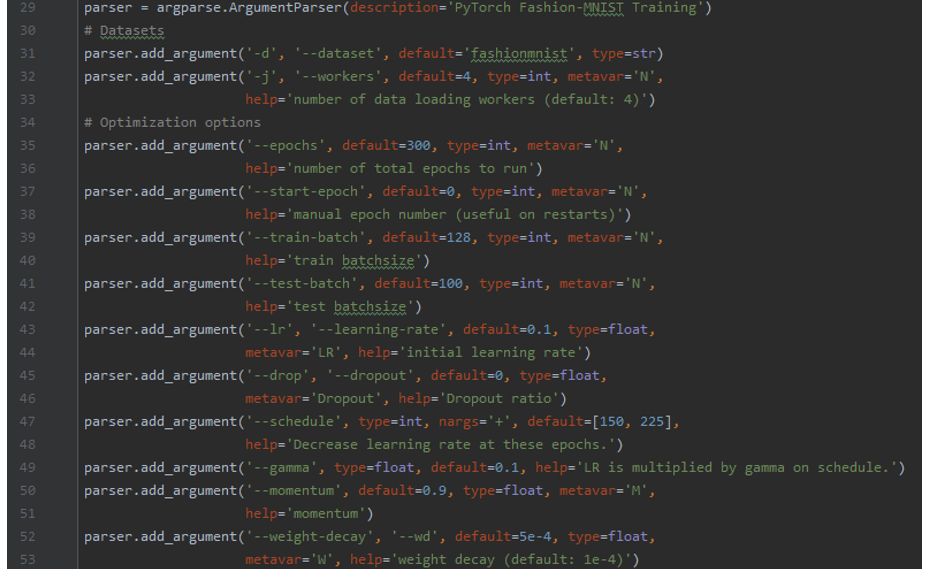
그리고 위에서 설명한 WRN 학습모델을 적용했다.

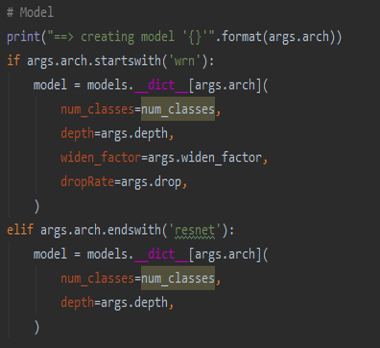
위 코드를 설명하면,
학습모델 : WRN
하이퍼 파라미터에서 설정한 값들로 모델을 생성
최적화 함수는 SGD
손실함수는 CrossEntropy 사용
Learning Rate : 0.1
Epoch : 300
으로 설정하였다.
왜 이렇게 설정했다고 묻는다면.... 이 글을 쓰기전에 몇가지 테스트를 진행했는데 이렇게 했을때 결과가 제일 좋았다... ㅎㅎㅎ
결론은 다음과 같다.
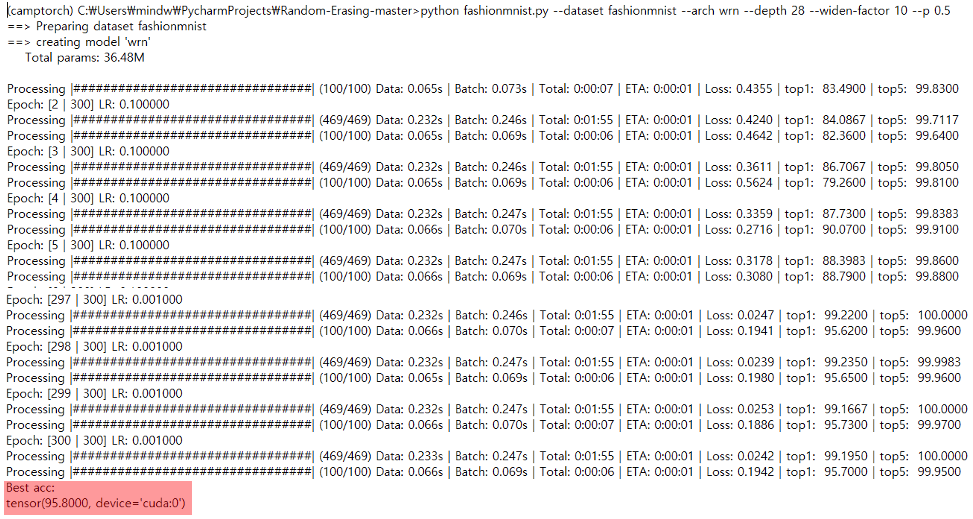
실제 벤치마크 결과보다는 낮지만 사용해본 모델들 중 가장 높은 95.8%가 나왔다. 감격...
'AI-딥러닝 > 실습(학습모델 비교)' 카테고리의 다른 글
| 데이터 셋 분석 및 학습 비교(8) - 정리 및 개선 (0) | 2021.06.13 |
|---|---|
| 데이터 셋 분석 및 학습 비교(5) - Batch_size와 Epoch의 변화에 따른 정확도 변화와 keras_library(early stopping) (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(4) - Keras CNN 사용 및 결과 분석 (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(3) - keras Sequential Dense Net사용 및 정확도 분석 (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(2) - 딥러닝이 필요한 이유와 단순(SoftMax Classification Model)적용 (0) | 2021.06.12 |