2021. 6. 12. 02:23ㆍAI-딥러닝/실습(학습모델 비교)
단순히 학습모델을 정해 놓고 테스트를 돌려보는 것은 의미가 없다..
진짜 딥러닝이 왜 필요한지를 알고 시작하는 것이 중요하다고 생각한다..
일단 단순히 SVM(SVC) 서포트 벡터 머신(support vector machine)으로 데이터 셋을 분류해 보았다.
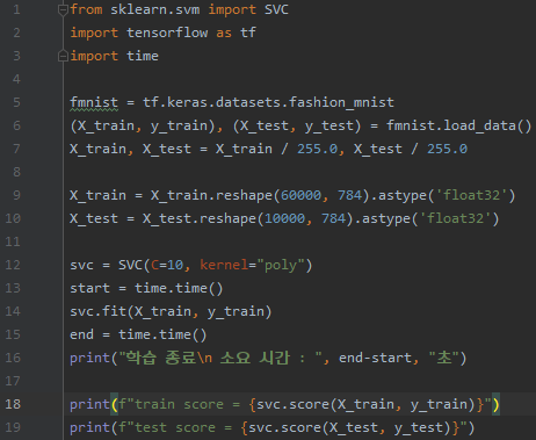
5~6행 : Fashion MNIST 데이터 셋 LOAD
9~10행 : X_train (60000, 784), X_test (10000, 784)으로 Reshape
12~14행 : Train alc Test 실행

분석 결과 DashBoard(89.7%)(VGGnet을 돌렸을 때) 보다 다소 낮은 정확도를 보인다. (88%) 얼마 차이는 안나지만...
즉, 이차이를 통해서 우리는 두가지를 알 수 있다.
데이터 전처리의 차이와 sklearn SVM의 성능 차이이다. 여기서 우리는 머신러닝 모델의 한계를 느끼고, 분류 성능이 부족함을 알 수 있다.
즉 다시말하면.... 분류 성능이 뛰어난 딥러닝 모델이 필요하다!
자, 간단한 학습모델부터 적용해보자!! 처음 적용할 모델은 "SoftMax Classification Model"이다
이 모델은
Layer 2개의 가벼운 모델이며,
최적화 함수: Adam
활성화함수 : Softmax
손실함수 : Crossentropy
Epoch : 100
Batch_size : 1000 으로 테스트를 진행했다.

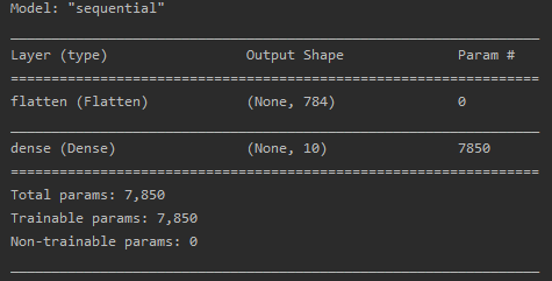
결과는 다음과 같이 나왔다.

예상대로 (84.69%)로 낮은 정확도를 보인다....
즉, 이것으로 모델의 깊이가 얕다는 것을 증명할 수 있다. 우리는 더 깊고 섬세한 학습모델을 적용해야한다....
'AI-딥러닝 > 실습(학습모델 비교)' 카테고리의 다른 글
| 데이터 셋 분석 및 학습 비교(7) - 새로운 딥러닝 모델 탐색 (0) | 2021.06.12 |
|---|---|
| 데이터 셋 분석 및 학습 비교(5) - Batch_size와 Epoch의 변화에 따른 정확도 변화와 keras_library(early stopping) (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(4) - Keras CNN 사용 및 결과 분석 (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(3) - keras Sequential Dense Net사용 및 정확도 분석 (0) | 2021.06.12 |
| 데이터 셋 분석 및 학습 비교(1) - VGGNet 분석 (0) | 2021.06.12 |